
15 Jun Semantic text and image search with AI & vector databases
In the world of databases, Monin has long been acquainted with SQL, noSQL, and newSQL databases, each addressing specific aspects of data management. However, a new player has emerged on the scene: vector databases. These innovative databases offer solutions to challenges that many businesses encounter in today’s data-driven world.
Two particular scenarios where traditional databases struggle are semantic and image search. This is where vector databases shine. They’re designed to efficiently tackle these very challenges, making them a compelling option for businesses seeking solutions that go beyond the limitations of conventional databases.
In this article, we invite you to embark on a journey of discovery into the world of vector databases. We’ll unravel the intricacies of how they excel in solving problems related to semantic and image search, and we’ll showcase their potential to revolutionize your data management strategies. Whether you’re in e-commerce, content management, recommendation systems, or any industry that relies on sophisticated search capabilities, vector databases may hold the key to unlocking new levels of efficiency and innovation.
The need for a vector index
Let’s begin by understanding the role of vectors in modern machine learning. Vectors, or embeddings, are utilized to represent information in a way that captures similarities between related data points. The image below illustrates this concept in a 2D example, showing how similar concepts are grouped together. In practice, computers use about a thousand numbers to represent all kinds of nuanced concepts.
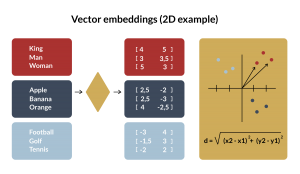
Representing similar information in a mathematical way makes them invaluable for search operations. Unlike traditional databases where exact matches are sought, vector databases enable the discovery of nearest matches. This abstract feat enables some pretty amazing applications:
- Semantic text search means you are now able to search through unstructured documents without having to rely on exact keywords. Coupled with a technology like ChatGPT you can then build intelligent question answering systems based on your data.
- Image search previously involved laborious tagging and the addition of keywords to supplement the images. However, we can now bypass the intermediary step and establish a direct connection between natural search queries and your image database. Gone are the days when locating that ideal picture hinged solely on the effectiveness of your search and tagging processes.

In practice, vector databases handle millions or even billions of vectors, each comprising approximately 1000 floating-point numbers. These vectors need to be compared against a given query vector.
Unfortunately, existing software tools fall short when it comes to efficiently executing such search operations on a database. Traditional SQL database systems are optimized for hash-based searches or 1D interval searches, making them impractical for vector-based operations.
To achieve the desired performance, an efficient index or an entire database optimized for similarity search is required. By sacrificing some accuracy and deviating slightly from the reference result, similarity search can be accelerated by orders of magnitude. This involves preprocessing the dataset, a process known as indexing.
When it comes to vector searches, there are three crucial metrics to consider: speed, memory usage, and accuracy. Speed refers to the time required to find the top 10 (or any other specified number) most similar vectors to a given query. The goal is to achieve faster results than what a brute-force algorithm would provide; otherwise, there would be no point in indexing. Memory usage is another critical factor, as efficient vector search primarily relies on RAM rather than disk-based databases, which are significantly slower. Finally, accuracy measures how well the returned results match those of a brute-force search.
Vector databases – vector similarity search from scratch
Multiple solutions exist for combining vectorized similarity search with SQL databases, including libraries such as txtai and pgvector. Txtai provides a comprehensive framework that integrates vector indexes with SQLite databases, as demonstrated in their article on the anatomy of a txtai index. On the other hand, pgvector offers a solution tailored specifically for PostgreSQL databases, allowing developers to effortlessly construct vector indexes and perform efficient similarity search operations within the SQL framework. These versatile options provide developers with flexibility in incorporating similarity search functionality into their SQL databases.
However, for production-ready applications, a solution specifically designed from the ground up to support vector databases is essential. Fortunately, vector databases cater to this need and are gaining rapid traction in the market. Numerous new players with significant funding have emerged, but currently, our top three contenders are Pinecone, Milvus, and Weaviate. We’ll keep the deep dive into each of these for another day, but be sure to let us know if you want to know more about their features and differences.
These vector database solutions simplify data storage and search by automatically calculating and storing vector representations. Moreover, they are mature products that offer the full suite of features one would expect from a production-ready database, including replication, high availability, and response & uptime SLA guarantees.
When to use vector databases in your business?
While vector databases provide unique capabilities, it’s important to note that they are not intended to replace SQL databases. Instead, they serve as complementary solutions for specific use cases. Vector databases excel in scenarios that require similarity search, semantic search, recommendation systems, and handling large-scale vector data efficiently. Here are some scenarios where vector databases shine and can bring significant benefits to your organization:
- Semantic Search Systems: If your business heavily relies on search functionality, vector databases can revolutionize the way you deliver relevant results to your users. With semantic search, you can enable intuitive and context-aware searches that go beyond exact keyword matching. By leveraging the similarity search capabilities of vector databases, you can provide more accurate and personalized search results or recommendations based on the similarity of vectors representing user preferences or item attributes.
- Natural Language Processing (NLP) Applications: NLP tasks such as sentiment analysis, text classification, document clustering, or language generation often require the comparison and analysis of text embeddings. Vector databases excel in efficiently handling large-scale text data and enabling fast similarity search based on vector representations. They can greatly accelerate the processing and analysis of textual information, enabling you to build sophisticated NLP-powered applications with ease.
- Large Language Model Memory: One such sophisticated application that has become very mature in a short amount of time is the use of vector databases in conjunction with Large Language Models (LLMs) like ChatGPT. LLMs tend to hallucinate when dealing with factual information, but can be supplied with context as part of the conversation. By vectorising your conversation, LLMs can be supplied with context from your database, allowing it to formulate responses that are fact-based and accurate.
- Image and Multimedia Retrieval: When dealing with image or multimedia data, vector databases become indispensable. Similarity search algorithms based on visual embeddings enable tasks like reverse image search, content-based image retrieval, or visual recommendation systems. Vector databases can efficiently index and search through vast collections of visual data, enabling users to find visually similar images or discover relevant multimedia content quickly.
- Anomaly Detection and Fraud Prevention: Vector databases can play a crucial role in anomaly detection and fraud prevention applications. By representing normal behavior or patterns as vectors, you can identify deviations or anomalies by measuring the similarity of new data points to the reference vectors. This allows for real-time monitoring and early detection of suspicious activities or fraudulent behavior, helping safeguard your business and mitigate potential risks.
- Personalization and Customer Experience Enhancement: Delivering personalized experiences to your customers is a key differentiator in today’s competitive landscape. Vector databases enable you to capture user preferences, behaviors, or interactions as vectors and use them to power recommendation engines, personalized content delivery, or targeted marketing campaigns.
Are vector databases SQL, no SQL or something else entirely?
Determining the precise categorization of vector databases within the existing database landscape is a challenging task. Mathematically speaking, SQL and noSQL cover all possible categories, leaving little room for additional classifications. By definition, vector databases fall under the noSQL category since they deal with lots of unstructured data and do not primarily deal with exact queries in the SQL format. However, if we look at some of the established noSQL categories (document, columnar, key-value, graph, etc.) we quickly find that vector databases do not align with any of them. A new noSQL category is born!
From an ontological perspective, one could argue for grouping most existing databases under the “Exact Search” category while creating a separate “Similarity Search” category for vector databases. However, this categorization becomes blurred due to the existence of vector indexes for SQL databases and the fact that vector databases also support boolean search operators. This seems to be a recurrent theme though, as this mirrors a similar blurring between SQL and noSQL databases (like Oracle Converged Database can do both SQL and NoSQL, anyone?).
Ultimately, the specific classification becomes less significant in practice, as the true value lies in the capabilities and advantages that vector databases bring to the table, rather than fitting them into predefined categories.
Conclusion
From a database administrator’s (DBA) perspective, the core principles of managing and optimizing database systems remain largely unchanged. Regardless of the type of database employed, businesses still require skilled professionals to monitor their systems, ensure optimal performance, and address any emerging issues.
At Monin, we understand the evolving landscape of databases and the importance of having a knowledgeable team to navigate these complexities. With our expertise in database management, including SQL and noSQL, we can provide comprehensive support to businesses in optimizing their database systems. Our experienced DBAs can assist in fine-tuning performance, implementing efficient indexing strategies, ensuring data consistency and integrity, and managing the overall health of your databases.
As a database service provider, we like to stay up-to-date with emerging technologies such as vector databases. It’s important for us to inform our customers about the possibilities they offer, as we’re doing in this blog post. If a technology brings added value, we are always keen to incorporate it into our portfolio.
Whether you are considering adopting emerging technologies like vector databases or seeking to enhance the performance of your existing database infrastructure, Monin’s database expertise can provide valuable guidance and support.
Contact us today to explore how we can help you leverage the power of databases for your business’s success!