
11 Dec Database design for Microsoft SQL Server: doing it right from the start!
A best practice overview from our Microsoft SQL Server expert Christian Vandekerkhove.
Whether you like it or not, your database is the fundamental part of your application. If you get it wrong it will cost you dearly in the end. A lot of money can be saved by following these base design rules:
Normalize your database
Nothing is more tempting than going for the good old quick & dirty method where you create tables and fields on the fly. You want to develop fast in order to save money, don’t you? Anyway you’re going to take care of everything via your application…
This method works remarkably well…until your database get’s a bit more complicated. Suddenly you’ll find yourself working long hours to adapt your application in order to take care of all the loose ends in your database design. Instead of gaining time you’re spending a lot of unplanned time debugging and adding code to your application. In the end you have a lot of almost unreadable code requiring a person with an IQ over 150 to understand the business logic.
Database normalization is old but gold. This method was created by Edgar F. Codd in 1970 and improved over the years. On the internet you’ll find numerous sites which explain this method.
A normalized database has the following advantages:
- Updates run quickly due to no data being duplicated in multiple locations.
- Inserts run quickly since there is only a single insertion point for a piece of data and no duplication is required.
- Tables are typically smaller that the tables found in non-normalized databases. This usually allows the tables to fit into the buffer, thus offering faster performance.
- Data integrity and consistency are guaranteed and do not need to be maintained by your application(s).
Use naming conventions
The saying goes: “code is written once but read a thousand times”. So be sweet to yourself and your colleagues and give meaningful names to your objects. Moreover by prefixing your objects it will be instantly clear whether you’re dealing with a table, view, stored procedure, etc. Here is an example:
| Prefix | Object type |
| tb_ | Table |
| pk_ | Primary Key |
| fk_ | Foreign key |
| uc_ | Unique constraint |
| ix_ | Index |
| uix_ | Unique index |
| st_ | Stored procedure |
| uf_ | User defined function |
| vw_ | View |
| ti_ | Insert trigger |
| tu_ | Update trigger |
| td_ | Delete trigger |
| df_ | Default |
| cc_ | Check constraint |
A habit that is unfortunately still widespread among developers, is the tendency to put “sp_” as a prefix of a stored procedure. There are actually several reasons why this is considered a bad practice in SQL Server. Dixit Microsoft:
Avoid the use of the sp_ prefix when naming procedures. This prefix is used by SQL Server to designate system procedures. Using the prefix can cause application code to break if there is a system procedure with the same name.
To make matters worse:
A user-defined stored procedure that has the same name as a system stored procedure and is either nonqualified or is in the dbo schema will never be executed; the system stored procedure will always execute instead.
Choose the correct data type
The most easy way is to use varchar(max) for all your fields. In almost all cases you’ll be able to store whatever you want in any field. Unfortunately there are some drawbacks with this method. E.g.: calculations on numeric data, working with dates, checking constraints, etc.
The good news is that SQL Server comes with a range of data types fitted for every occasion. Moreover there are many built-in functions which can work with these data types saving you many hours of development.
Still, within this range of possibilities, one should choose wisely. As a rule of thumb, always go for the tiniest possible datatype. E.g.: a byte is sufficient to store shoe sizes, you don’t need a bigint for that. If you’re not familiar with the data types in SQL Server, have a look at the books online:
https://docs.microsoft.com/en-us/sql/t-sql/data-types/data-types-transact-sql?view=sql-server-ver15
Another nasty habit found in developers is that they love to use (N)VARCHAR to store information which really belongs in a (N)CHAR field. Here are some good reasons to use (N)CHAR instead of (N)VARCHAR:
- (N)VARCHAR is a variable length string. In each record the size for each (N)VARCHAR field is stored using 2 bytes. So if you use VARCHAR(1) then each record will consume 3 bytes in order to store 1 byte of information.
- (N)CHAR is a fixed length string. The information about the length is only stored once in the header of the table.
In a small database you won’t notice any effect. However in large databases all this storage waste will add up and will affect your performance.
Get rid of obsolete data types
Do yourself a pleasure and get rid of the following datatypes: (N)TEXT and IMAGE. They have been around for a long time and although Microsoft has been stating for many year that they are going to be removed in a future version, they are still supported in SQL Server 2019.
Still, you should replace them with (N)VARCHAR(MAX) and (N)VARBINARY(MAX). It will make your coding easier. Also these datatypes are implemented more efficiently.
Index your foreign keys
One of the processes in database normalization is that you define relations between tables. This is done by using foreign keys. While this is a good thing to do, be aware of a performance pitfall. E.g.: every time a record is deleted in the parent table, SQL Server will check whether the child table contains a reference to the deleted primary key. If so, the transaction will be rolled back. The key point is that SQL Server needs to access the child table to verify this. If in the child table, the foreign key is not indexed, a table or clustered index scan will be performed which will degrade your performance.
Enable and check your foreign keys
If you need to perform huge bulk insert operations, it might be a good idea to temporarily disable your foreign key constraints in order to speed up the load operation. However it’s crucial that after this operation you not only enable your foreign key but also check your foreign key:
- Enabling the foreign key means that from now on, every insert/update/delete operation will be checked.
- Checking the foreign key means that all data in the child table will be verified against the primary key of the parent table in order to verify that your data is still consistent. If this is not done, your foreign key will be marked as “untrusted” and the optimizer might decide to not use the index on your foreign key => performance degradation.
Remove duplicate indexes
It’ worth checking if your table doesn’t contain duplicate indexes:
- Defining two or more identical indexes will not improve performance.
- All insert/update/deletes will be at least two times slower.
- The superfluous index(es) will be ignored by SELECT statements.
- Disk space is being wasted to store these unused indexes.
Note that an unique index is automatically created in the following circumstances:
- When you define a primary key constraint
- When you define an unique constraint.
When you define a foreign key however, an index is not created automatically.
Don’t create indexes > 900 bytes
Technically it is possible to create an index where the maximum length of the fields exceeds 900 bytes. Doing this might jeopardize the good functioning of your application as INSERT & UPDATE statements will be rejected if they contain too much data:
Msg 1946, Level 16, State 3, Line 1
Operation failed. The index entry of length 901 bytes for the index ‘ix_myindex’ exceeds the maximum length of 900 bytes.
Limit the size of your clustered index/key
Be aware that when you create a clustered index or key, every non-clustered index will contain a reference to this key. If your clustered index is relatively big, it will consume a lot of storage in your non-clustered indexes as well.
If your primary key is clustered and is relatively big, consider replacing it by a technical key. In this method you add e.g. an int or bigint as the primary key and replace the original primary key with a non-clustered unique constraint.
SELECT *
This is my favorite query in non-PROD and for ad-hoc queries. However this query should never be present in your views, stored procedures, functions nor in your application code:
- If extra fields are added to the table, the result set will return more columns than expected resulting in a runtime error!.
- If the order of the columns in the table changes (e.g.: after the table has been dropped and recreated), the SELECT will return the same number of columns but in a different order resulting in a wrong handling of the data.
- Lastly: are you sure you need all the columns? Always limit your result set to only return what you really need.
Always define your columns in your INSERT statements
I know it’s a bit more work to type but always clearly define which fields you’re going to insert. The same 2 reasons apply as for the “SELECT *” topic.
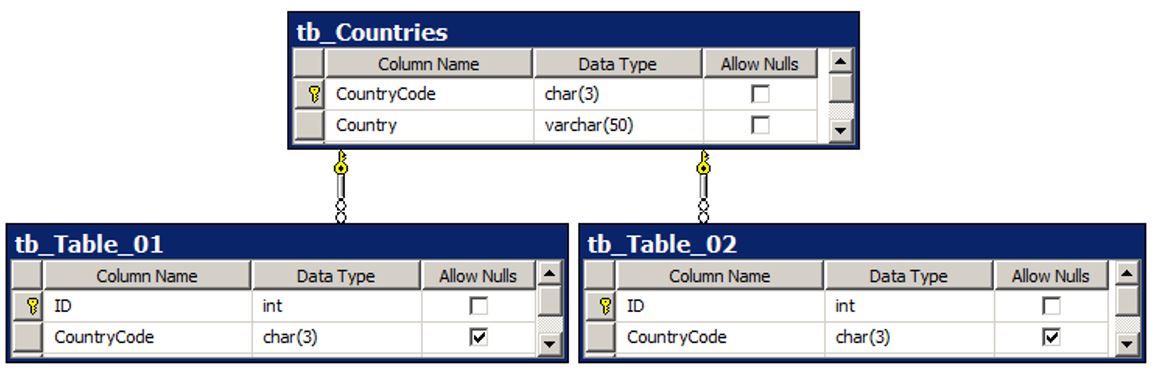
Have a look at duplicate column names
Especially if they have different data types. E.g.: if the field CountryCode is a CHAR(3) but in another table the datatype is a varchar(10), you probably missed something during your normalization process.
E.g.:
WRONG

CORRECT
Hopefully this gives you some more insights on how to design your database from the start. But what about your existing databases? A manual checkup can already show you what should be modified. However, this manual checkup can be a time-consuming process. Using the Monin Microsoft SQL tooling the process can be automated and combined with the expert knowledge of our Microsoft SQL Server experts, providing you with an action plan as deliverable. Just let us know if we can help and Contact us by phone: +32 3 450 67 89 or via e-mail: info@monin-it.be